We introduce a high resolution, 3D-consistent image and shape generation technique which we call StyleSDF. Our method is trained on single-view RGB data only, and stands on the shoulders of StyleGAN2 for image generation, while solving two main challenges in 3D-aware GANs: 1) high-resolution, view-consistent generation of the RGB images, and 2) detailed 3D shape. We achieve this by merging a SDF-based 3D representation with a style-based 2D generator. Our 3D implicit network renders low-resolution feature maps, from which the style-based network generates view-consistent, 1024×1024 images. Notably, our SDF-based 3D modeling defines detailed 3D surfaces, leading to consistent volume rendering. Our method shows higher quality results compared to state of the art in terms of visual and geometric quality.
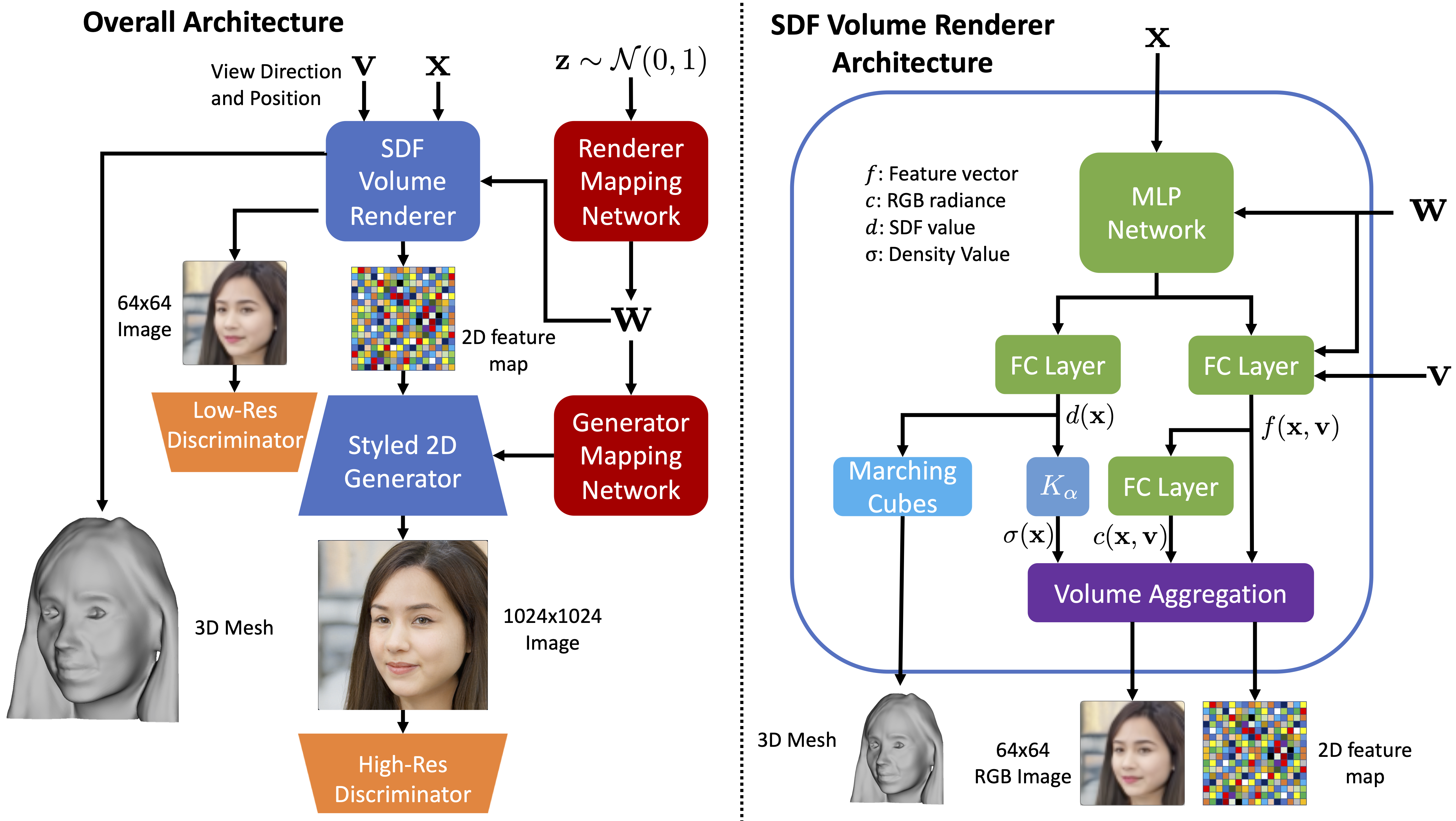
Our framework consists of two main components. A backbone conditional SDF volume renderer, and a 2D stylebased generator. Each component also has an accompanied mapping network to map the input latent vector into modulation signals for each layer. To generate an image, we sample a latent vector z from the unit normal distribution, and camera azimuth and elevation angles (ϕ, θ) from the dataset’s object pose distribution. For simplicity, we assume that the camera is positioned on the unit sphere and directed towards the origin. Next, our volume renderer outputs the signed distance value, RGB color, and a 256 element feature vector for all the sampled volume points along the camera rays. We calculate the surface density for each sampled point from its SDF value and apply volume rendering to project the 3D surface features into 2D feature map. The 2D generator then takes the feature map and generates the output image from the desired viewpoint. The 3D surface can be visualized with volume-rendered depths or with the mesh from marching-cubes algorithm.
The following videos present the appearance and geometry of 3D content generated by StyleSDF with random sampling. Note that the geometry is rendered from depth maps that are obtained via volume rendering for each view.
Even though the generated images on multi-view RGB generation look highly realistic, we note
that for generating a video sequence, the random noise of StyleGAN2, when naıvely applied to 2D images, could
result in severe flickering of high-frequency details between frames.
The flickering artifacts are especially prominent for the AFHQ dataset due to high-frequency textures from the
fur patterns.
Therefore, we aim at reducing this flickering by adding the Gaussian noise in a 3D-consistent manner, i.e., we want
to attach the noise on the 3D surface. We achieve this by extracting a mesh (at 128 resolution grid) for each sequence
from our SDF representation and attach a unit Gaussian noise to each vertex, and render the mesh using vertex coloring.
Since higher resolution intermediate features require up to 1024×1024 noise map, we subdivide triangle faces of
the extracted mesh once every layer, starting from 128×128 feature layers.
The video results show that the geometry-aware noise injection reduce the flickering problem on the AFHQ dataset,
but noticeable flickering still exist. Furthermore, we observe that the geometry-aware noise slightly sacrifices individual
frame’s image quality, presenting less pronounced high-frequency details, likely due to the change of the Gaussian
noise distribution during the rendering process.
@InProceedings{orel2022styleSDF,
title = {Style{SDF}: {H}igh-{R}esolution {3D}-{C}onsistent {I}mage and {G}eometry {G}eneration},
author = {Or-El, Roy and
Luo, Xuan and
Shan, Mengyi and
Shechtman, Eli and
Park, Jeong Joon and
Kemelmacher-Shlizerman, Ira},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {13503-13513}
}
}
